您需要 登录 才可以下载或查看,没有账号?注册
更多精彩内容需要登录后查看
查看全部评分
老ぁ狗
kala
使用道具 举报
kala 发表于 2013-7-7 22:58 除非你用raid卡,那安全性可能会高很多,但是这不在nas的范畴,nas现在价格已经离谱,如果再把raid芯片集成 ...
lasttime 发表于 2013-7-7 23:21 这是精品论坛沙大的精华帖子,而精品论坛 严禁“未经CCF论坛同意,禁止私自采集使用CCF论坛帖子内容。”
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
0
4653
1
nas技术牛人
nas高手技术牛人
退休版主
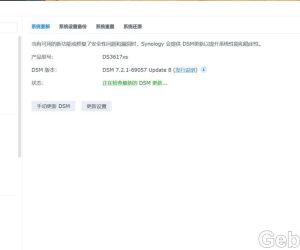 为什么DS3617xs DSM7.2.1-69057update8在安1538 人气#黑群晖
为什么DS3617xs DSM7.2.1-69057update8在安1538 人气#黑群晖 BTSCHOOL开放注册2天221 人气#PTer交流
BTSCHOOL开放注册2天221 人气#PTer交流 求一个馒头的药101 人气#PTer求邀
求一个馒头的药101 人气#PTer求邀 【诚心求彩虹岛CHD邀请】本人PT经验10年以122 人气#PTer求邀
【诚心求彩虹岛CHD邀请】本人PT经验10年以122 人气#PTer求邀



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡
